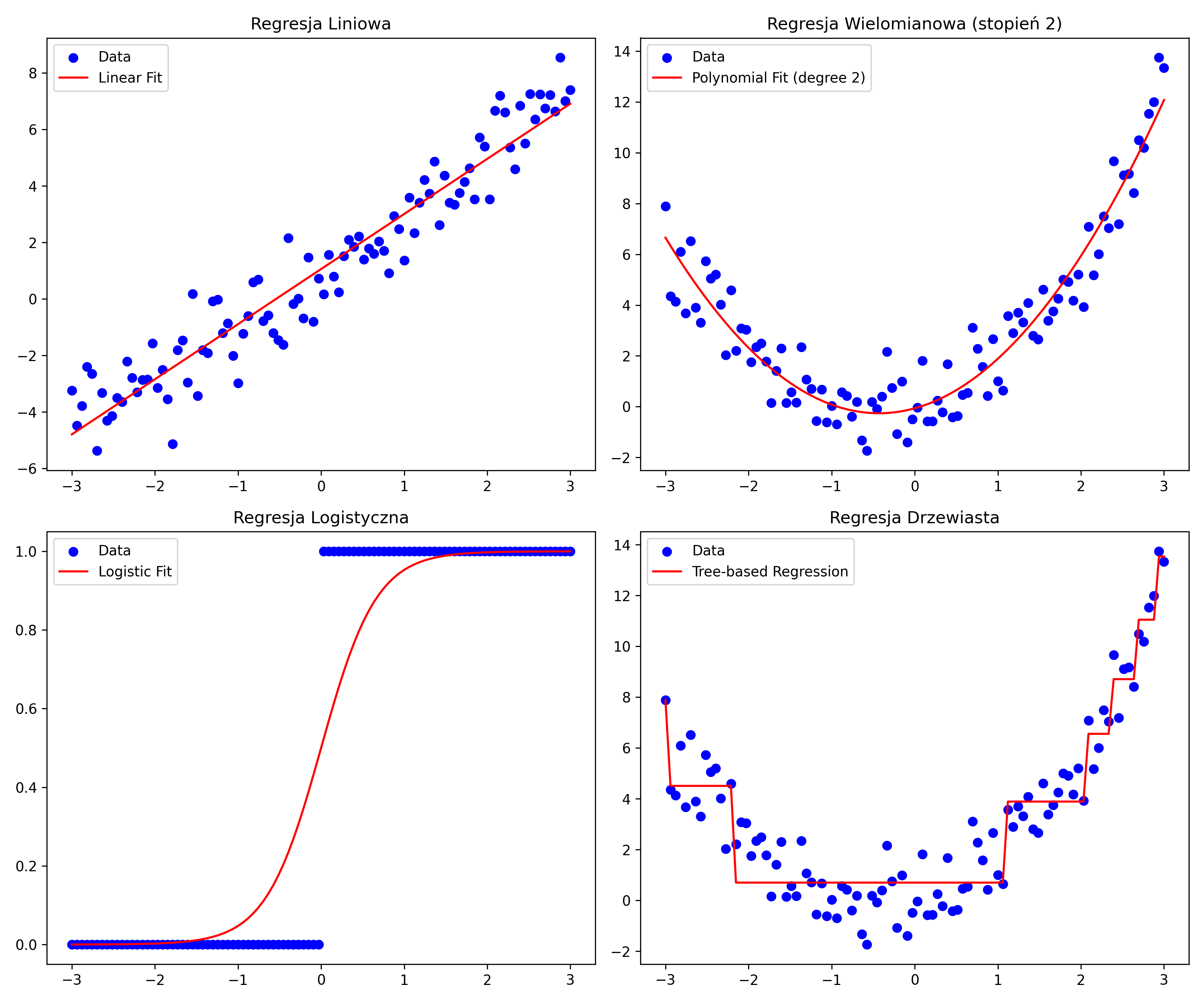
Rodzaje regresji
Istnieją różne rodzaje regresji, które różnią się rodzajem zależności między zmiennymi, które modelują. Najczęściej występujące to:
- Regresja liniowa: Podstawowy rodzaj regresji, w którym założeniem jest liniowa zależność zmiennych (czyli można ją przedstawić za pomocą prostej), np. droga i czas w ruchu jednostajnym prostoliniowym,
- Regresja wielomianowa: Służy do modelowania bardziej złożonych zależności, których nie można opisać przy pomocy prostej, np. wzrost człowieka i wiek,
- Regresja logistyczna: Służy do przewidywania wartości binarnych (tak/nie, 0/1), np. czy stwierdzenie czy uda się przejechać drogę o danej długości bez tankowania,
- Regresja drzewiasta: Buduje model w postaci drzewa decyzyjnego, co pozwala na interpretację wyników, np. predykcja ceny domu, gdzie każdy węzeł jest pytaniem o jedną z cech (metraż, wiek, etc.).
Aby łatwiej było zrozumieć różnice, poniżej znajdują się przykładowe wykresy z wrysowanymi poszczególnymi typami regresji
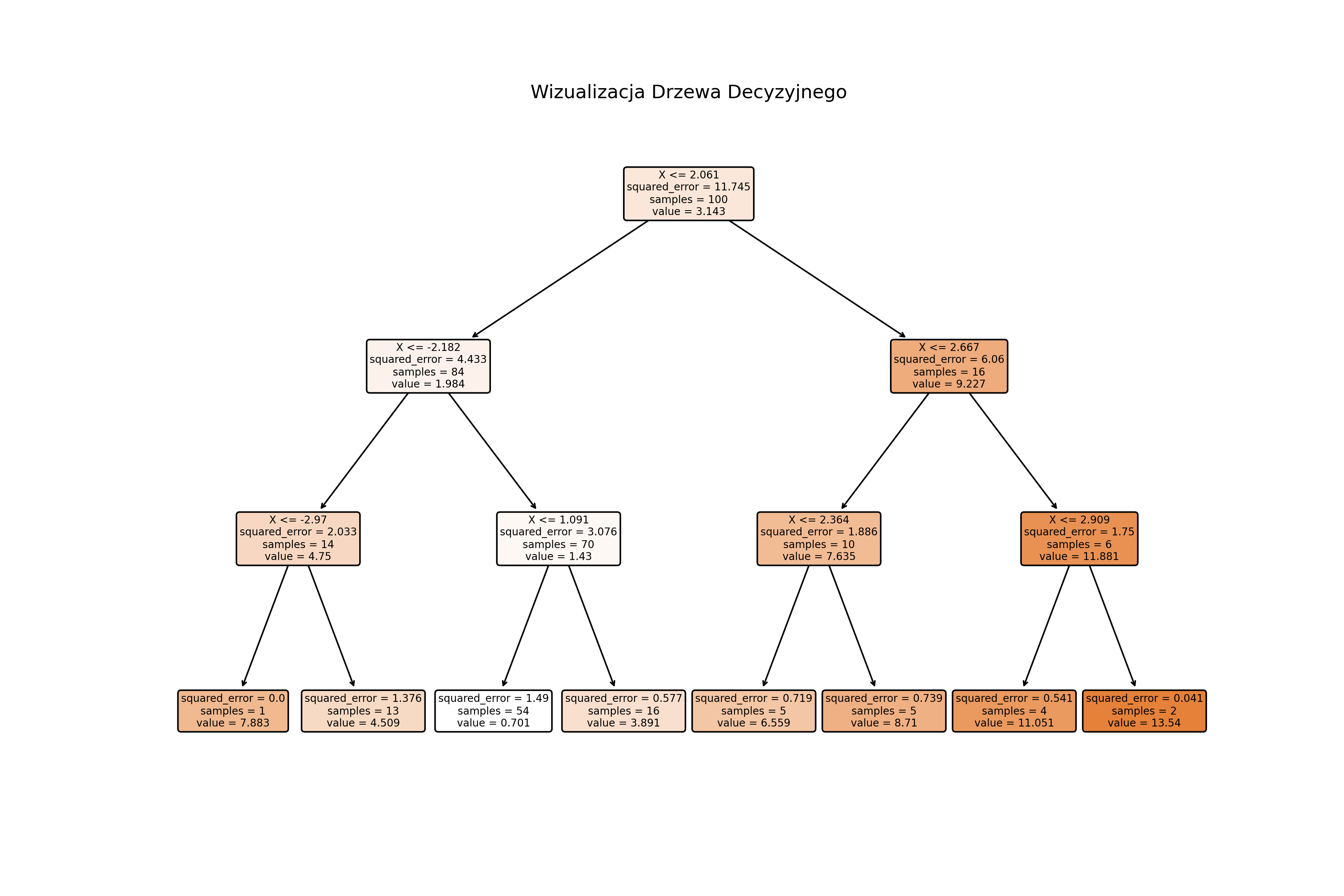
A na grafice poniżej widoczna jest wizualizacja drzewa decyzyjnego z przykładu powyżej, gdzie widać jak parametru x wpływa na wartość przewidywaną przez drzewo. Taki "schodkowy" przebieg regresji wynika z głębokości drzewa równej zaledwie max_depth=3, więc max 8 wartości na wyjściu.
Algorytmy ML, które można zastosować do regresji
Drzewa decyzyjne (Decision tree)
Drzewo decyzyjne, to taki algorytm, który dzieli dane na mniejsze grupy na podstawie warunków logicznych. Model ma strukturę drzewa, w którym każdy węzeł reprezentuje kolejne pytania, gałęzie prowadzą do odpowiedzi, a w liściach znajdują się predykcje.
Dobrym przykładem może być utworzenie drzewa do klasyfikacji zwierząt. Załóżmy, że chcemy mieć następujące klasy (na klasach jest łatwiej wytłumaczyć niż na regresji, ale różnica jest taka, że predykowana jest wartość, a nie klasa): kot, pies, sowa, orzeł, pająk, mrówka, wąż, dżdżownica. Drzewo decyzyjne mogłoby wyglądać następująco:
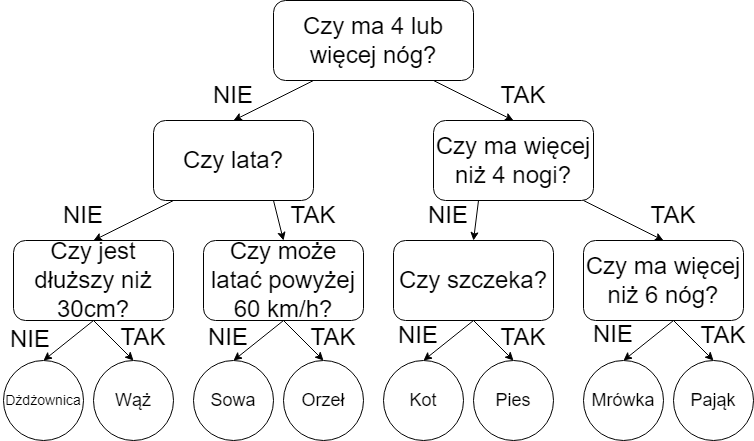
Zaletami drzew decyzyjnych jest możliwość wykorzystania zarówno cech numerycznych, jak i kategorycznych, oraz łatwość w interpretacji modelu. Wadą jednak jest podatność na przeuczenie (overfitting), które polega na zbyt mocnym dopasowaniu modelu do danych treningowych. Korzystając z rysunku powyżej, przeuczenie mogłoby się objawić tym, że pies, który przez jakiś czas badania nie zaszczekał, zostanie zakwalifikowany jako kot, bo w taki sposób zostało dobrane pytanie podczas treningu.
Las losowy (Random forest)
Random Forest polega na budowie wielu niezależnych drzew decyzyjnych, a następnie łączeniu ich wyników (poprzez uśrednianie dla regresji lub głosowanie większościowe dla klasyfikacji). Każde drzewo w lesie jest trenowane na losowym podzbiorze danych i atrybutów, co pomaga modelowi unikać przeuczenia. Inną zaletą jest to, że dobrze radzi sobie z dużymi zestawami danych, które mają dodatkowo dużo cech.
Maszyna wektorów nośnych (Support Vector Machine - SVM)
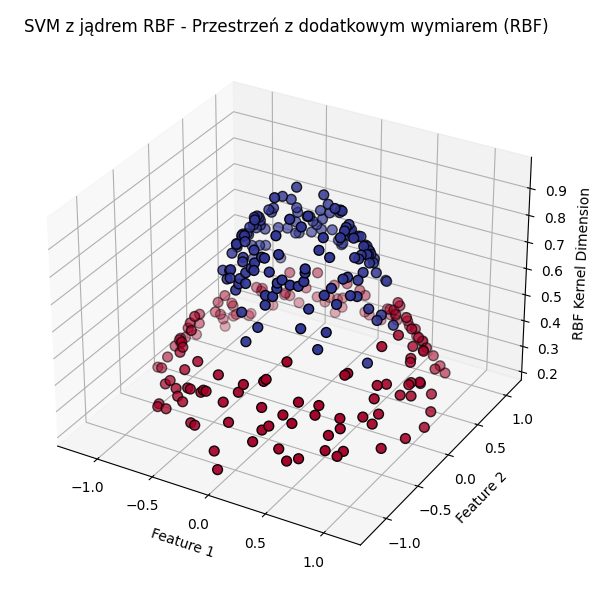
SVM to algorytm, który stara się znaleźć hiperpłaszczyznę w przestrzeni wielowymiarowej, która najlepiej oddzieli poszczególne klasy w danych. W przypadku problemów liniowych, SVM szuka płaszczyzny, która maksymalizuje odległość między najbliższymi punktami dwóch klas. Zaletą jest to, że SVM może korzystać z kerneli (jąder), które pozwalają na transformację danych do wyższych wymiarów, aby znalezienie płaszczyzny było możliwe dla problemów nieliniowych. Wadami jest jednak trudność w interpretacji oraz większa złożoność obliczeniowa.
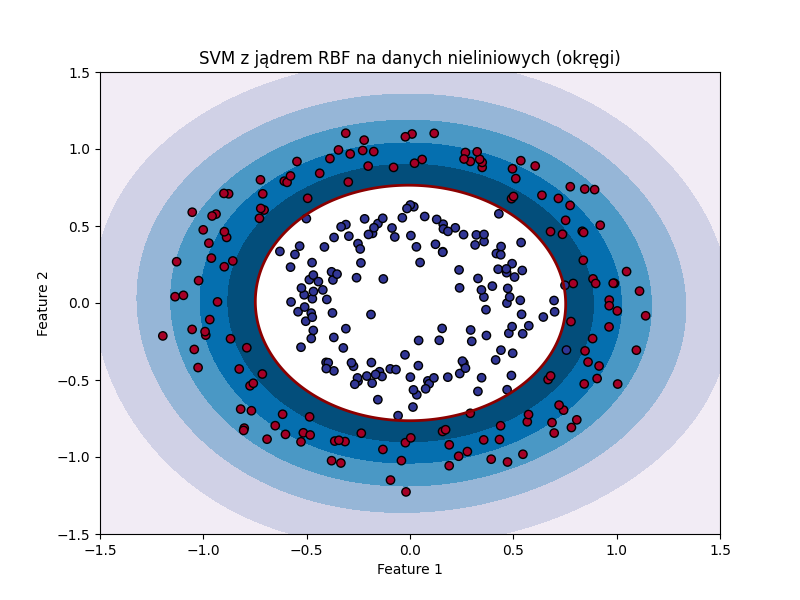
Przykład jak algorytm SVM działa dla danych, w których występują 2 klasy, które oddzielić należy za pomocą okręgu, a nie liniowo pokazany jest poniżej. Poprzez wykorzystanie jądra RBF (Radial Basis Function) możliwe jest dodanie kolejnego wymiaru, w którym znaleziona zostaje hiperpłaszczyzna, która oddzieli dane na poszczególne klasy.
Co dalej?
Przejdź do kolejnego zagadnienia (Czym jest Scikit-learn) lub kliknij tutaj, aby wrócić do strony głównej tematu.